Transformations
Mathematical Conventions
Generic Transformations
Transformations are denoted in general as functions 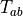 .
In this case, is the frame-forward transformation from frame
.
In this case, is the frame-forward transformation from frame  to frame
to frame 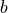 , also shown in Fig. 1.
, also shown in Fig. 1.

Fig.1: Transformations between different frames.
The concatenation of multiple transformations is denoted as
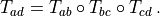
Since we use frame-forward transformations, 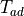 expressed as multiplication of homogeneous transformation matrices (HMs) yields
expressed as multiplication of homogeneous transformation matrices (HMs) yields
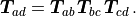
This also implies that a point 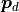 in frame
in frame 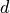 is transformed to frame using
is transformed to frame using
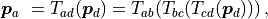
or expressed as HMs using
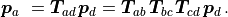
The inverse of a transformation is denoted as
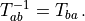
Motions and Poses
The TransformContainer makes it possible to store transformations as either motions or poses and to convert between both representations. Fig. 2 gives an overview over the relation between motions and poses.
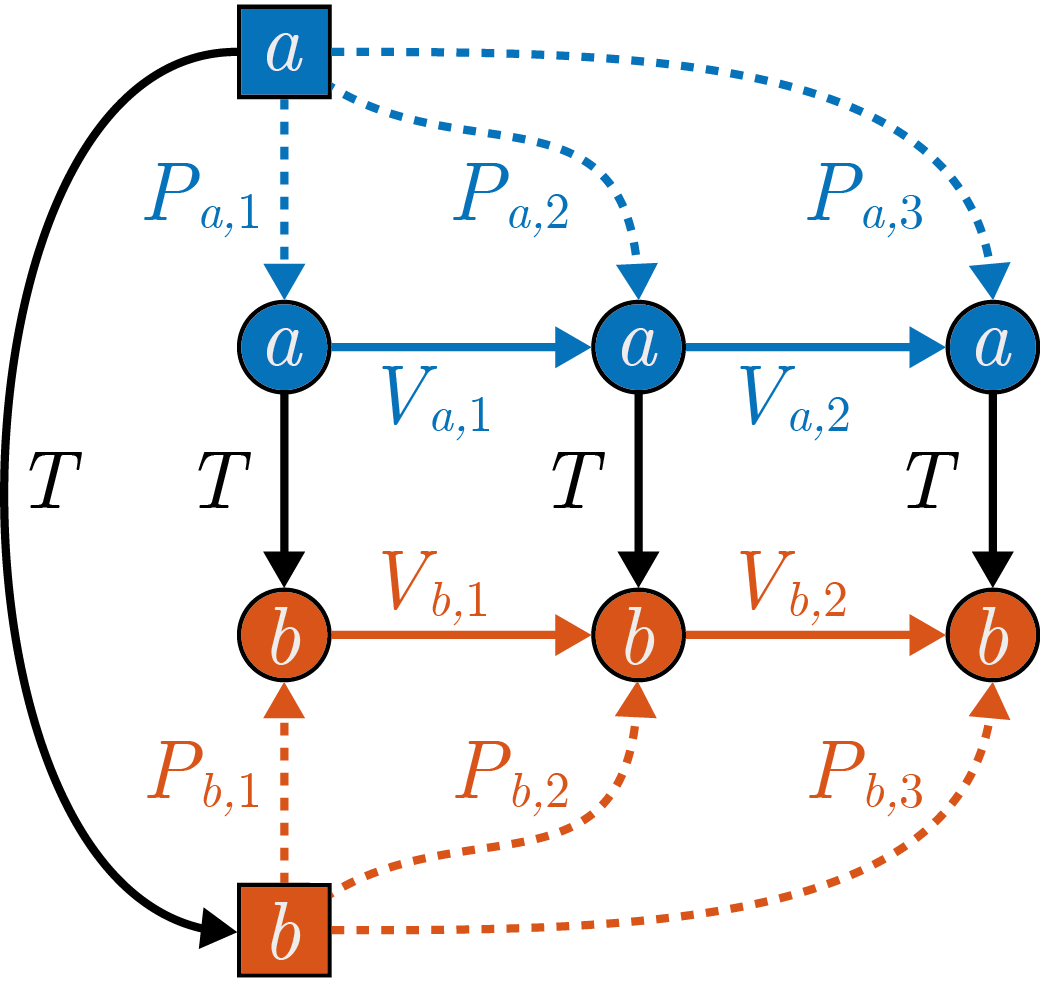
Fig. 2: Motions and poses.
The pose of a frame at step 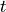 is denoted as
is denoted as 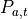 , the motion between two poses at step is denoted V_{a,t}.
Thus, the motion between two poses is calculated as
, the motion between two poses at step is denoted V_{a,t}.
Thus, the motion between two poses is calculated as
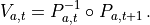
Vice versa, the next pose, given the previous pose and the motion, is calculated as
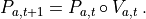
When converting a full dataset from motions to poses, the initial pose 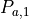 must be provided.
The identity transformation is a trivial choice for this.
must be provided.
The identity transformation is a trivial choice for this.
In case of two rigidly coupled frames and as in Fig. 2, e.g., sensors mounted on a vehicle, the respective motions and poses can be converted into each other
using the rigid frame transformation 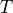 :
:
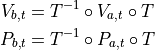
Representations
A transformation representation is necessary for using and applying the previously described generic transformations. The following table lists all implemented transformation representations. Some representations do not directly support operations like concatenation or inversion. However, they are implicitly converted by this library to other representations for this. We refer to the respective documentation of each class for more detailed information.
Representation |
Class |
|---|---|
Axis-Angle Rotation and Translation Vector |
|
DualQuaternion |
|
Euler Angles and Translation Vector |
|
Homogenous Matrix |
|
Quaternion and Translation Vector |
Implementation
Representations
For each representation, a separate class is implemented.
Furthermore, in order to enable representation-independent processing, all these classes inherit from motion3d::TransformInterface.
This makes it possible to store, access, modify and combine transformations without taking care of the underlying representation.
The asType() methods of each class can be used to convert between the different representations.
For maximizing performance, it is still necessary to convert transformations to a fixed representation, since the usage of motion3d::TransformInterface involves vtable access.
We recommend to use either motion3d::DualQuaternionTransform or motion3d::MatrixTransform for this, since they provide direct implementations for all possible operations instead of converting to a different representation first.
Single Transformations
Transformations are created using either the respective constructors or the motion3d::TransformInterface::Factory() method.
The default constructor automatically initializes an identity transformation.
By default, transformations are marked as safe.
This means that at each operation, the transformation is automatically checked for validity.
The unsafe parameter of the constructors can be used to disable this.
However, this can lead to errors since most operations only work properly on valid transformations.
A safe and valid transformation can be obtained using the normalized() methods.
The following table gives an overview of possible operations on single transformations.
Operation |
Equation |
Implementation(s) |
|---|---|---|
Apply |
|
|
Apply |
|
|
Invert |
|
|
Apply |
|
|
Translation norm of |
|
|
Rotation norm of |
|
|
Scale translation of |
|
|
Normalize |
|
 after
after 
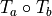
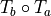
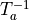
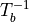 after
after 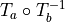
Transformation Container
In addition to the previously described operations on single transformations, motion3d::TransformContainer also provides container specific functions.
Description |
Implementation |
|---|---|
Apply |
|
Change the coordinate frame using the rigid frame transformation |
|
Get container as poses with the identity pose as initial pose |
|
Get container as poses with the |
|
Get container as motions |
|
More methods, e.g., involving stamped data, can be found in the motion3d::TransformContainer documentation.
Inplace Operations
All previously described method do not alter the original objects.
For performing operations directly on the object, some methods have an inplace variant, marked by a trailing underscore, e.g., normalized_() instead of normalized().